Pandas is a one of the most popular software library extension of Python. Wes McKinney designed it in 2008. It helps manipulate and analyze stored data.
“Pandas” stands for Panel Data, which means an Econometrics from Multidimensional data. According to the official pandas documentation, it is “a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive.
Pandas aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python. It has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way towards this goal.”
Pandas can load, manipulate, prepare, model, and analyze data. It allows loading data from CSV, Excel, JSON, HTML, SQL, SAS, SPSS, STAT, ORC, Google BigQuery, clipboard, Pickle and many more. And analyze those data to produce a result which can be in the form of table, text, etc.
It is great for wrangling (data cleaning in simple words) and manipulating data. It can:
- Handle large datasets.
- Quickly clean data and convert file formats.
- Combine with BeautifulSoup to dump text from a scraper into a database.
- Visualize data with Matplotlib.
It provides two major data structures, both of these data structures are built on top of the NumPy:
Series: One-dimensional array of values with an index.
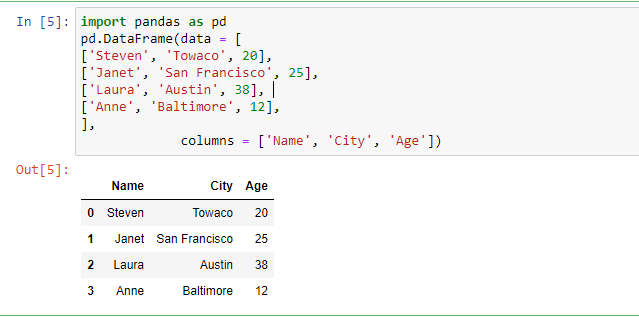
DataFrames: Multi-dimension array of values with both a row and column index
Installation of Pandas
Installing with Anaconda
For inexperienced users, installing Pandas and rest of its dependent package like NumPy can be difficult .
The simplest and easiest way to install Python along with Pandas, and the most popular packages that make up the SciPy stack (like IPython, NumPy, Matplotlib,) is with Anaconda. Its free version has all the tools and libraries that you need to get started. We can use pandas straight away after installing Anaconda.
Installing with Miniconda
The above approach installs hundreds of package along with Python. If you have limited bandwidth or space or want more control over package, then with Minoconda you can install only the packages that’s needed. However, it involves many steps. For complete procedure of installing visit here.
Installing from PyPI
You can install Pandas from PyPI via following command
pip install pandas
Checking installation
To check if Pandas has installed correctly, run the following command. If it works fine, then you are ready for hands on experience with Pandas
import pandas as pd
pd : is an alias to the Pandas.
Uses of Pandas
- Load and save data in to multiple file/database formats.
- Can insert or delete any column in the existing datasets.
- Can select or filter rows and column.
- Rename rows and column.
- Remove/add a certain row/column in the datasets.
- Sort the data in ascending or descending order.
- Find and manage missing values.
- Help manage duplicate values.
- As a data scientist it is most important to understand datasets much better by exploring them, Pandas is very helpful in this purpose.
- Can visualize the data.
Advantages of Pandas
- Streamlined forms of data representation.
- Less writing and more work done
- Makes data flexible and customizable
- Handling large data efficiently.
- Various tools to support data load into data objects irrespective of their file formats..
- Data indexing of higher volume dataset.
- Pivot and Reshape datasets.
- Can read & write in many data formats (integer, float, double, string, etc.)
- Select subsets of data from large data sets and even combine multiple datasets together.
- Perform operations on rows and column.
- It can find and fill missing data.
- It supports advance time-series functionality.
Conclusion:
Pandas is a Python module that makes data science easy and effective. It’s an open source library. It is the core library for data manipulation and data analysis. Pandas is mainly used in Finance, Analytics and Economics firms.

C P Gupta is a YouTuber and Blogger. He is expert in Microsoft Word, Excel and PowerPoint. His YouTube channel @pickupbrain is very popular and has crossed 9.9 Million Views.