
Pandas is the most preferred Python library for data analysis. The reason is its core data structure called DataFrame, one of the two basic data structure of Pandas. It’s 2-dimensional labeled data structure with columns of potentially different types.
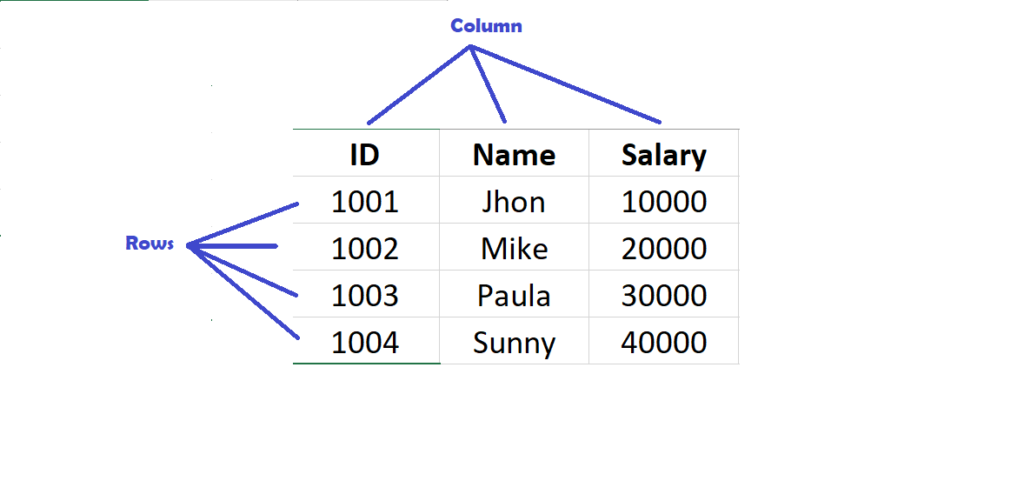
DataFrame is a widely used data structure of Pandas and works with a two-dimensional array with labeled axes (rows and columns). Defined as a standard way to store data and has two different indexes, i.e., row index and column index. It comprises the following properties:
- The columns can be of heterogeneous types like int, float, string and boolean.
- 2-Dimension Data structure with rows and columns
- Rows are denoted as ‘Index” while columns are simply denoted as ‘Colums’
In simple words, DataFrame is like a spreadsheet or table with feature to name rows and columns.
Why do we need it?
Let’s take an example to understand the use of Pandas. We have a 5 randomly select patient data. The insurance company is trying to predict how many females will be there by the end of the year.
# Header -> 'Bill_Amount','Sex','Bed_Number','Age'
data = [[ 10000, 'M', 1, 59],
[ 11000, 'F', 5, 31],
[ 25000, 'F', 4, 45],
[ 75000, 'M', 3, 27],
[ 12000, 'F', 10, 18]]
print(data)
# Output
>>>[[10000, 'M', 1, 59],
>>> [11000, 'F', 5, 31],
>>> [25000, 'F', 4, 45],
>>> [75000, 'M', 3, 27],
>>> [12000, 'F', 10, 18]]
Above data is efficiently contained in the list, but it doesn’t give insight into the data analyst about the variables.
import pandas as pd
data = [[ 10000, 'M', 1, 59],
[ 11000, 'F', 5, 31],
[ 25000, 'F', 4, 45],
[ 75000, 'M', 3, 27],
[ 12000, 'F', 10, 18]]
df = pd.DataFrame(data, columns = ['Bill_Amount','Sex','Bed_Number','Age'])
print(df)
#Outut
>>> Bill_Amount Sex Bed_Number Age
0 10000 M 1 59
1 11000 F 5 31
2 25000 F 4 45
3 75000 M 3 27
4 12000 F 10 18
On converting list into Pandas DataFrame, tabular data structure of a Pandas DataFrame organizes data in the form of rows and column. This data shows that Insurance company are looking for Bill Amount, Sex, Bed Number and Age as Key Variable.
This is just an example, there are many more reasons to use DataFrames.
Benefits
The benefits of Pandas DataFrame are:
- Easy to visualize the data from a DataFrame.
- Quickly analyze data using a variety of inbuilt function
- DataFrame object can be of mixed data types unlike NumPy arrays which need to be homogenous.
- It allows to clean data and convert it into a tidy structure.
- Handling missing values.
- Encoding categorical data
- Working with Datetimes
Creating DataFrame
We can create pandas DataFrame from the csv, excel, SQL, list, dictionary, and from a list of dictionary etc. Here are some ways by which we can create a dataframe:
Creating an Empty DataFrame
This is a simple example to create an empty DataFrame in Python.
#Creating an Empty DataFrame
import pandas as pd
data = pd.DataFrame()
print(data)
#Output
Empty DataFrame
Columns: []
Index: []
Creating DataFrame by Comma Separated Value (CSV) File
To create a DataFrame from CSV file, use ‘read_csv’ method. This method reads CSV file into a DataFrame.
#Creating DataFrame by csv file
import pandas as pd
df = pd.read_csv('CompleteCricketData.csv')
print(df)
# Output
Unnamed: 0 Player ... Date Unnamed: 15
0 0 RG Sharma ... 11/13/2014 NaN
1 1 MJ Guptill ... 3/21/2015 NaN
2 2 V Sehwag ... 12/8/2011 NaN
3 3 CH Gayle ... 2/24/2015 NaN
4 4 Fakhar Zaman ... 7/20/2018 NaN
... ... ... ... ...
Above code required minimum one argument, i.e.relative path name of CSV file. In above case, CSV file is saved on the same folder Python script. However, if it is located inside a sub folder name ‘subFolder’ then path name would be ‘subFolder/CompleteCricketData.csv’
Creating DataFrame by Excel File
To create a DataFrame from Excel file, use ‘read_excel’ method. It is like above method. It reads Excel file into a DataFrame.
#Creating DataFrame by excel file
import pandas as pd
df = pd.read_excel('SampleData.xlsx')
print(df)
# Output
Unnamed: 0 Player ... Date Unnamed: 15
0 0 RG Sharma ... 11/13/2014 NaN
1 1 MJ Guptill ... 3/21/2015 NaN
2 2 V Sehwag ... 12/8/2011 NaN
3 3 CH Gayle ... 2/24/2015 NaN
4 4 Fakhar Zaman ... 7/20/2018 NaN
... ... ... ... ...
Creating DataFrame by Python List
We can create the DataFrame using a single list or a list of lists.
#Creating DataFrame by list
import pandas as pd
sample_list1 = [1,2,3,4,5]
df = pd.DataFrame(sample_list1)
print(df)
#Output
0
0 1
1 2
2 3
3 4
4 5
#Creating a DataFrame by list of lists.
import pandas as pd
sample_list2 = [['Mike',10000],['Jhon',20000],['Paula',30000]]
df = pd.DataFrame(sample_list2 ,columns=['Name','Salary'])
print(df)
#Output
Name Salary
0 Mike 10000
1 Jhon 20000
2 Paula 30000
Creating DataFrame by Python Dictionary
We can pass dictionaries as input data to create a DataFrame. The dictionary keys are by default taken as column names.
To create DataFrame from dictionary of array/list, all the array must be of same length. When passed, the length of index should be equal to the length of arrays. Default index will be range(n) where n is the array length.
#Creating DataFrame by dictionary without index
import pandas as pd
sample_data = {'Name':['Jhon', 'Nick', 'Mike', 'Paula'],
'Salary':[10000, 20000, 30000, 40000]}
df = pd.DataFrame(sample_data)
print(df)
#Output
Name Salary
0 Jhon 10000
1 Nick 20000
2 Mike 30000
3 Paula 40000
#Creating DataFrame by dictionary with index
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 50, 'b': 60, 'c': 70}]
df = pd.DataFrame(data, index=['first', 'second'])
print(df)
#Output
a b c
first 1 2 NaN
second 50 60 70.0
Creating DataFrame by Dictionary of List
We declared four lists of elements and then assigned them for each column.
import pandas as pd
Name = ['John', 'Nike', 'Mike', 'Paula']
Age = [25, 32, 30, 26]
Office = ['Microsoft', 'Amazon', 'Google', 'Spotify']
Salary = [1000000, 1200000, 900000, 1100000]
table = {'Name': Name,
'Age': Age,
'Office Name': Office,
'Salary': Salary
}
data = pd.DataFrame(table)
print(data)
#Output
Name Age Office Name Salary
0 John 25 Microsoft 1000000
1 Nike 32 Amazon 1200000
2 Mike 30 Google 900000
3 Paula 26 Spotify 1100000
Creating DataFrame by Tuple List
In the code below, each element of the list is tuple. These tuple is a row in DataFrame. Default column name are assigned using range(n), where n is length of each tuple.
#Creating DataFrame by tuple
import pandas as pd
sample_list = [('Mike',10000),('Jhon',20000),('Paula',30000)]
df = pd.DataFrame(sample_list ,columns=['Name','Salary'])
print(df)
#Output
Name Salary
0 Mike 10000
1 Jhon 20000
2 Paula 30000
We have covered 7 different ways of creating pandas DataFrame. There are more ways to create DataFrame, you can check Pandas documentation to learn more about creating a Pandas DataFrame.

C P Gupta is a YouTuber and Blogger. He is expert in Microsoft Word, Excel and PowerPoint. His YouTube channel @pickupbrain is very popular and has crossed 9.9 Million Views.