
No matter how much we love Python, we all agree that Python is Slow!!! Why? Higher level language features like dynamically typing and Python interpreter which makes Python user friendly also make it sluggish. Other reasons for being slow includes Global Interpreter Lock popularly known as GIL. All these makes Python much slower compared to compiled lower level language like C/C++ and Fortran.
Features like list comprehension speeds up Python code but finds limited use. Moreover, speed up gain is limited as it doesn’t address the above fundamental problem. But there are ways by which these bottle neck can be addressed and you can speed up Python code up to 1 Million times and practically achieve speed close to C/C++.
Numba and Cython to speed up Python
Dynamically typing (i.e. checking variable type at run time) and Interpreter of Python incurs a big penalty to its speed. Numba and Cython both, attack this problem to achieve huge speed up.
Cython
It provides a way to add static type declaration to Python program and then compile it to faster C/C++ extension (similar to NumPy) which can be imported in any Python program like any other Python modules. In short, Cython makes writing C extension for Python language as easy as Python itself. For more details on installation and tutorial on Cython visit here.
Numba
Numba is an open-source Just In Time (JIT) compiler. It speeds up Python and NumPy functions by translating to optimized machine code using industry-standard LLVM compiler library. The best part of Numba is that it neither needs separate compilation step nor needs major code modification.
In most case, Python function can be optimized by simply adding one-liner decorator above it. Moreover, it offers range of speed up option like vectorization and parallelizing Python code for CPU and CUDA supported GPU in one-liner decorator. For more details on installation and tutorial, visit 5 minute Numba guide.
Numba works best on code that uses Python Loops and NumPy arrays. It doesn’t speed up Python code that used other libraries like Pandas etc.
Benchmarking of Python speed up with Cython and Numba
To demonstrate, speed up of Python code with Cython and Numba, consider the (trivial) function that calculates sum of series.
# Cython Function
def series_sum_cython(int x):
cdef int y = 0
cdef int i
for i in range(x):
y += i
return y
from numba import njit
# Python Function
def series_sum_python(x):
y = 0
for i in range(x):
y += i
return y
# Numba Function
@njit(cache = True)
def series_sum_numba(x):
y = 0
for i in range(x):
y += i
return y
Compiling and static typing of Numba:
If you are seeing Numba code for the first time, you may be wondering “How one liner decorator solves static typing and compilation?”
When Numba code is called for the first time, Numba compiles code function for the given argument type into faster machine code. Hence first call to Numba function may take few additional seconds as it includes compilation time. However, once the compilation has taken place Numba caches the machine code version of your function for the particular types of arguments presented. When called again the with same argument types, Numba reuse the optimized cached version. All this optimization is achieved with just one word decorator “@njit”
Benchmarking Python, Cython and Numba
Lot of benchmarking result are available on internet. However, many result includes, one time compilation time of Numba code into benchmark. This is one of the common mistake done while profiling Numba code which results in huge underestimation of Numba performance.
# Speed Benchmarking Code
# PickupBrain
from numba import njit
# Compiled Cython Function
from sum_series import sum_series_cython
from timeit import timeit
#Python Function
def sum_series_python(x):
y = 0
for i in range(x):
y += i
return y
# Numba Function
@njit(cache = True)
def fib_numba(x):
y = 0
for i in range(x):
y += i
return y
pytime = []
cytime = []
nbtime = []
def test_speed(n):
setup_str = 'from __main__ import fib_python, fib_numba, fib_cython'
for x in range(n):
pyfun = 'sum_series_python('+str(int(10**x))+')'
nbfun = 'sum_series_numba('+str(int(10**x))+')'
cyfun = 'sum_series_cython('+str(int(10**x))+')'
pytime.append(timeit(pyfun, setup=setup_str, number = 3))
cytime.append(timeit(cyfun, setup=setup_str, number = 5))
nbtime.append(timeit(nbfun, setup=setup_str, number = 5))
test_speed(10)
Python vs Cython vs Numba
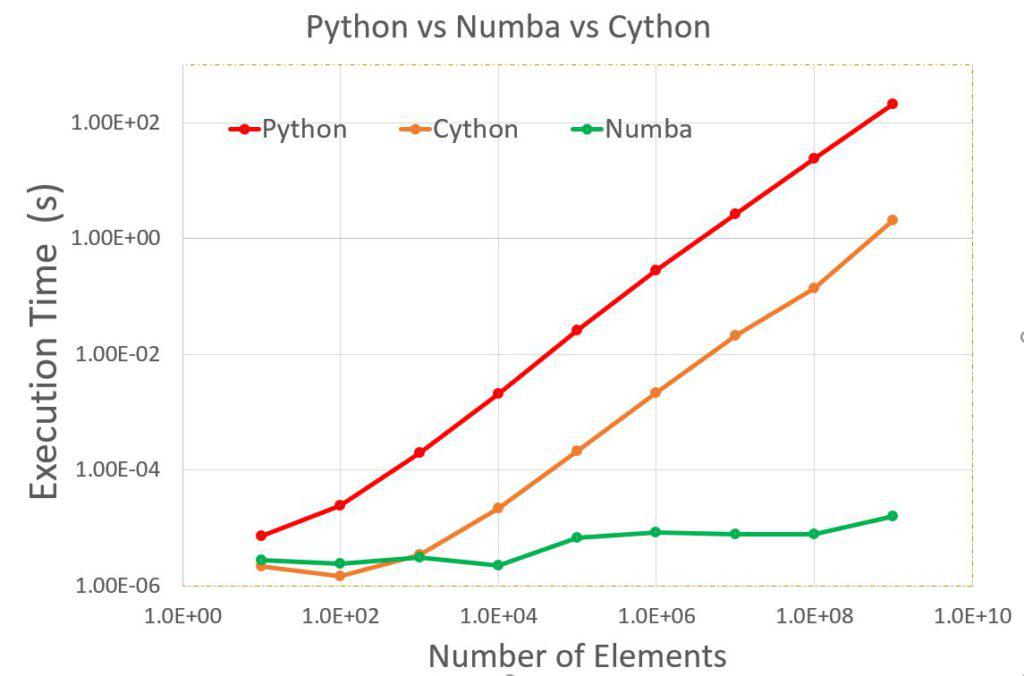
Following benchmark result shows Cython and Numba library can significantly speed up Python code. Computation time for Python and Cython increase much faster compared to Numba. As computation increase, speed up grain also increases. For 10^9 elements of series, which is too much of computation, Python code takes around 212 sec while Cython and Numba code takes only 2.1 s and 1.6E-5 s respectively.
Speed up Python code
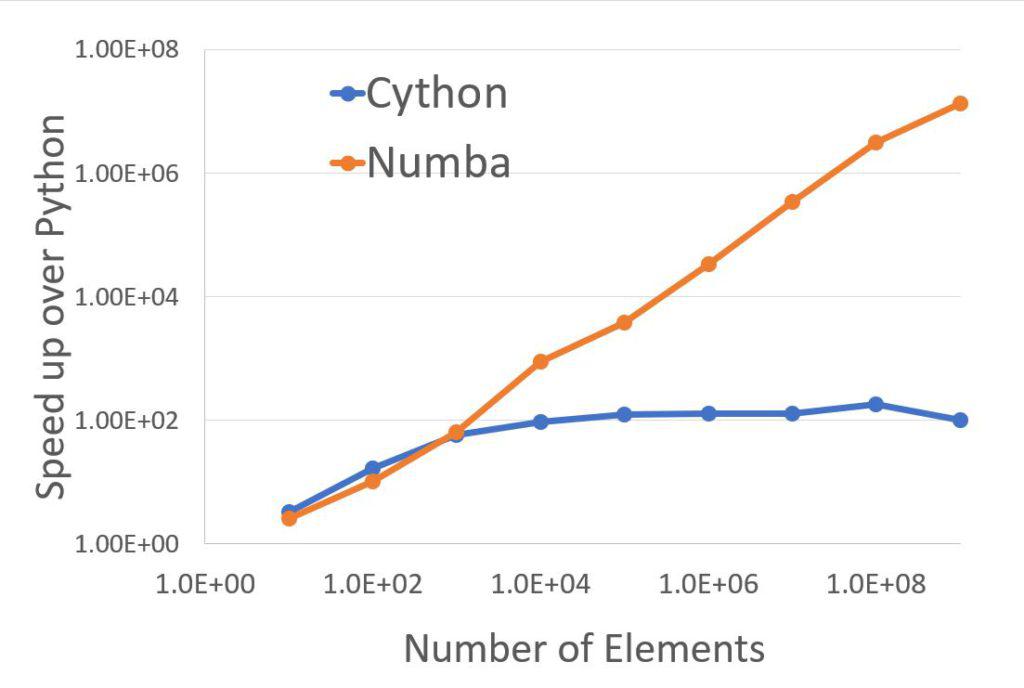
Both Cython and Numba speeds up Python code even small number of operations. More the number of operations more is the speed up. However, performance gain by Cython saturates at around 100-150 times of Python. On the other hand, speed up gain by Numba increases steadily with number of operations. Cython and Numba achieves speed up of 110 and 13 Million times.
Cython v/s Numba
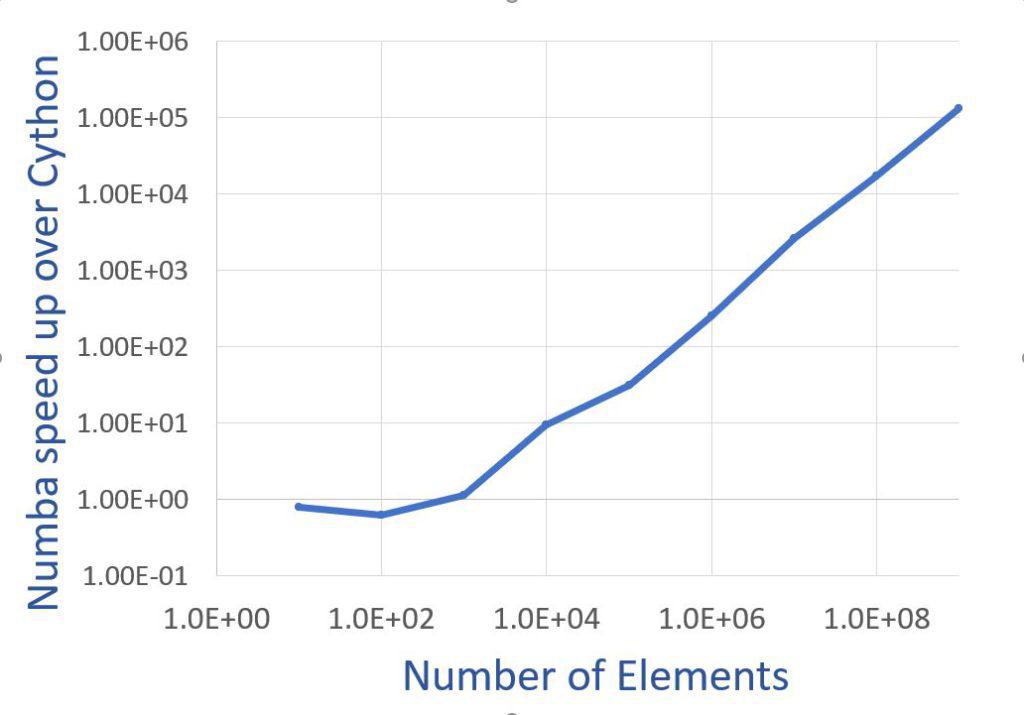
Numba is relatively faster than Cython in all cases except number of elements less than 1000, where Cython is marginally faster.
Summary
Numba and Cython can significantly speed up Python code. Static typing and compiling Python code to faster C/C++ or machine code gives huge performance gain. Speed up increases with increase in number crunching. It is seen that Cython saturates to a speed up of around 150, when Numba continues to provide higher performance. For application with heavy number crunching, Numba provides speed of C/C++ with features of Python. In one of our benchmark case, Numba improved Python performance by over 13 Million times which too large to ignore.

C P Gupta is a YouTuber and Blogger. He is expert in Microsoft Word, Excel and PowerPoint. His YouTube channel @pickupbrain is very popular and has crossed 9.9 Million Views.
This is very useful info. Looks like numba rocks and it’s already in my current installation of python 3. Thank you!
Thanks dear for the comments. Yes, Numba rocks and I have been using this regularly.
Will numba increase brute force speed?
Welcome dear.